
type
status
slug
summary
tags
category
icon
password
new update day
Property
Oct 22, 2023 01:31 PM
created days
Last edited time
Oct 22, 2023 01:31 PM
Lab: Copy-on-Write Fork for xv6

首先看一下任务要求和描述
The problem
The fork() system call in xv6 copies all of the parent process's user-space memory into the child. If the parent is large, copying can take a long time. Worse, the work is often largely wasted: fork() is commonly followed by exec() in the child, which discards the copied memory, usually without using most of it. On the other hand, if both parent and child use a copied page, and one or both writes it, the copy is truly needed.
The solution
Your goal in implementing copy-on-write (COW) fork() is to defer allocating and copying physical memory pages until the copies are actually needed, if ever.
COW fork() creates just a pagetable for the child, with PTEs for user memory pointing to the parent's physical pages. COW fork() marks all the user PTEs in both parent and child as read-only. When either process tries to write one of these COW pages, the CPU will force a page fault. The kernel page-fault handler detects this case, allocates a page of physical memory for the faulting process, copies the original page into the new page, and modifies the relevant PTE in the faulting process to refer to the new page, this time with the PTE marked writeable. When the page fault handler returns, the user process will be able to write its copy of the page.
COW fork() makes freeing of the physical pages that implement user memory a little trickier. A given physical page may be referred to by multiple processes' page tables, and should be freed only when the last reference disappears. In a simple kernel like xv6 this bookkeeping is reasonably straightforward, but in production kernels this can be difficult to get right; see, for example, Patching until the COWs come home.
大概意思就是:xv6 中的 fork() 系统调用将父进程的所有用户空间内存复制到子进程中。如果父进程很大,复制可能需要很长时间。更糟的是,这项工作经常白白浪费:fork() 通常在子进程中紧接着就会调用 exec(),这会丢弃已复制的内存,通常不会使用其中的大部分。另一方面,如果父进程和子进程都使用已复制的页面,并且一个或双方都对其进行写操作,则确实需要复制。
然后我们需要使用 COW 解决方案:实现写时复制 (Copy-on-write, 简称 COW) fork() 的目标是在真正需要复制的时候再分配和复制物理内存页面,如果可能的话。
COW fork() 为子进程创建仅一个页面表,带有针对父进程物理页面的用户内存的 PTEs。COW fork() 将父进程和子进程中的所有用户 PTEs 标记为只读。当任一个进程试图写这些 COW 页面时,CPU 会强制产生页错误。内核页错误处理程序会检测到这种情况,为错误进程分配一个物理内存页,将原始页复制到新页中,并修改错误进程中的相关 PTE 以引用新页,这次将 PTE 标记为可写。当页错误处理程序返回时,用户进程将能够写入其页面的副本。
COW fork() 使释放实现用户内存的物理页面变得有点棘手。给定的物理页面可能被多个进程的页面表所引用,并应在最后一次引用消失时被释放。在像 xv6 这样的简单内核中,这种记录保持是相当直截了当的,但是在生产内核中,这可能会难以做到正确;具体可以参看 Patching until the COWs come home 一文。
给出的解决方案规划
看完了问题以及解决方案要求,下面就是课程给出的一个合理的解决方案
- 修改
uvmcopy(),使其将父进程的物理页映射到子进程,而不是分配新页面。对于设置了PTE_W的页面,清除子进程和父进程的 PTE 中的PTE_W。
- 修改
usertrap()以识别页面错误。当 COW 页面发生写页面错误时,使用kalloc()分配新页面,将旧页面复制到新页面,并在 PTE 中放置新页面并设置PTE_W。原始只读的页面(如文本段中的页面,未映射PTE_W)应保持只读并在父子进程之间共享;试图写入此类页面的进程应被杀死。
- 确保每一个物理页在最后一个 PTE 引用消失时被释放 - 但不要提前。一个好方法是为每个物理页面保持一个 "引用计数",表示引用该页面的用户页面表的数量。当
kalloc()分配页面时,将页面的引用计数设置为一。当 fork 导致子进程共享页面时,增加页面的引用计数,并在任何进程从其页面表中删除页面时,减小页面的计数。只有当页面的引用计数为零时,kfree()才能将页面重新放回空闲列表。将这些计数保留在一个固定大小的整数数组中是可以的。你需要制定一个方案来索引数组以及如何选择其大小。例如,你可以用页面的物理地址除以 4096 来索引数组,并给数组一个与kinit()在kalloc.c中放置在空闲列表上的任何页面的最高物理地址相等的元素数。你可以自由地修改kalloc.c(例如,kalloc()和kfree())来维护引用计数。
- 修改
copyout(),使其在遇到 COW 页面时,使用与页面错误相同的方案。
以下一些提示可能会有所帮助:
- 对于每一个 PTE,记录它是否是一个 COW 映射可能是很有用的。你可以用 RISC-V PTE 中的 RSW(为软件预留)位来实现这一点。
usertests -q可以测试 cowtest 没有测试的场景,所以别忘了检查所有测试是否都通过了。
- 一些有用的用于页面表标志的宏和定义在
kernel/riscv.h的末尾。
- 如果发生了 COW 页错误,但内存没有空闲空间,那么进程应该被杀死。
开始编码
PTE_C 的确定
对于每一个 PTE,记录它是否是一个 COW 映射可能是很有用的。你可以用 RISC-V PTE 中的 RSW(为软件预留)位来实现这一点。
ok,看完给出的提示和方案规划,那我们的第一步应该就是先确定 PTE_C 这个标志应该使用哪一位进行标志,可以看到第八位,第九位是 RSW 的状态,那么我们就选第 8 位作为, PTE_C ,即 COW 的标志位。
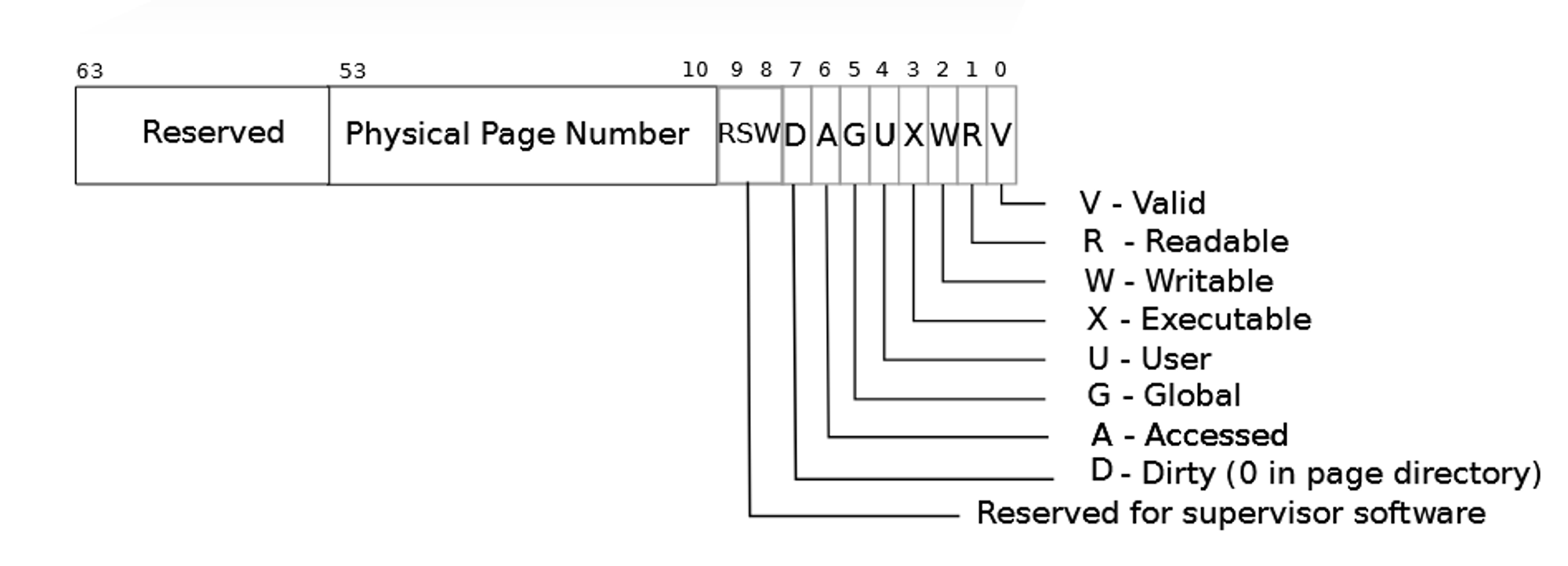
uvmcopy()
修改uvmcopy(),使其将父进程的物理页映射到子进程,而不是分配新页面。对于设置了PTE_W的页面,清除子进程和父进程的 PTE 中的PTE_W。
根据函数的注释,我们能看到这个函数的目的是根据父进程的页表,然后将对应的物理页面拷贝到子进程中去,我们现在所做的工作就是将父进程的页面设置成 COW 页面,并将父进程的物理页面同步映射到子进程的页面中去,并将物理页面的引用数+1,这样的话,就可以实现进程的 COW ,节省内存空间,并追溯页面的引用数。
将页面的
PTE_W 标志取消是为了引发页面错误,从而在需要更新的时候为子进程申请新的物理页面,保存新的内容。usertrap()
修改usertrap()以识别页面错误。当 COW 页面发生写页面错误时,使用kalloc()分配新页面,将旧页面复制到新页面,并在 PTE 中放置新页面并设置PTE_W。原始只读的页面(如文本段中的页面,未映射PTE_W)应保持只读并在父子进程之间共享;试图写入此类页面的进程应被杀死。
查找 RISC-V 的异常号,找到需要处理的异常号即 15 和 13,然后在用户陷阱函数处对其进行处理,判断是否需要进行 COW 相关处理。

cowalloc(pagetable_t pagetable, uint64 va)
这是 cow 页面处理函数,在发现页面错误的时候对其进行 COW 处理。
- kernel/defs.h
- kernel/vm.h
引用计数
确保每一个物理页在最后一个 PTE 引用消失时被释放 - 但不要提前。一个好方法是为每个物理页面保持一个 "引用计数",表示引用该页面的用户页面表的数量。当kalloc()分配页面时,将页面的引用计数设置为一。当 fork 导致子进程共享页面时,增加页面的引用计数,并在任何进程从其页面表中删除页面时,减小页面的计数。只有当页面的引用计数为零时,kfree()才能将页面重新放回空闲列表。将这些计数保留在一个固定大小的整数数组中是可以的。你需要制定一个方案来索引数组以及如何选择其大小。例如,你可以用页面的物理地址除以 4096 来索引数组,并给数组一个与kinit()在kalloc.c中放置在空闲列表上的任何页面的最高物理地址相等的元素数。你可以自由地修改kalloc.c(例如,kalloc()和kfree())来维护引用计数。
因为引用计数涉及到多个进程之间的操作,所以需要对其进行加锁和初始化。
因为是物理地址,的引用计数,所以我们可以使用
PHYSTOP/PGSIZE 作为数据大小的空间。- kernel/defs.h
- kernel/kalloc.c
- kfree()
- kalloc()
copyout()
修改copyout(),使其在遇到 COW 页面时,使用与页面错误相同的方案。
然后写这个函数的时候一定要注意一个点,就是
cowalloc() 和 walkaddr() 的顺序。如果我们在
cowalloc() 之前用 walkaddr() 来查找虚拟地址对应的物理地址,查到的物理地址其实是父进程的共享页帧。那么到时候就会往这个地址里写东西,造成错误(别的进程也会使用这个页帧)。
而在
cowalloc() 之后查找物理地址,查到的就是新分配的物理地址,写入的也是当前进程独有的页帧,不会影响别的进程。参考资料
- 作者:tangcuyu
- 链接:https://expoli.tech/articles/2023/07/25/%5BMIT-6.s081%5D-Lab%3A-Copy-on-Write-Fork-for-xv6-experiment-record
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章